


Data has now become the most asset that an enterprise can possess – raw data is useless unless there is a good mechanism to transfer it, transform it, and bring the data to the point where it is needed. This is what data pipeline architecture is designed to accomplish. It specifies the flow of data between source systems and destinations of analytical systems, how data is cleaned and molded in transit, and how well it is delivered on time. The more businesses become dependent on AI, real-time reporting, and intelligent automation, the better your pipeline architecture, the better your decisions will be. Get it wrong and all the downstream, your analytics, your AI models, your operational dashboards, are going to work as they should. Make a mistake, and you are always putting out a data fire rather than making it grow.
Data Pipeline Architecture Explained: More Than Just Moving Data
A short time ago, data pipelines were considered infrastructure issues – something that the engineering team did in the background. Such a mentality has evolved tremendously. Data pipeline architecture has become a strategic choice today with practical implications on the speed of a business to adapt, compete, and expand.
The global data pipeline tools market was valued at $14.76 billion in 2024 and is projected to reach $48.33 billion by 2030, growing at a CAGR of 26.8%. The fact that growth is this way indicates the level of urgency with which enterprises are trying to get this infrastructure right.
An effective modern data engineering pipeline is not just a data mover. It:
- Minimizes the time lag between the creation of data and its availability.
- Improves data reliability by catching quality issues before they reach downstream systems
- Scales are designed to scale as the data volumes, data sources, and use cases increase.
- Feeds models with clean, structured, and versioned data and supports AI and machine learning.
- Maintains a productive team by automating manual data work and observable workflows.
The reverse side is quite real. Architected improperly, data pipelines are likely to silently fail, drift, replicate logic, and run up enormous costs. It takes more time to debug a team than to build one, and business executives are forced to make decisions based on out-of-date or inaccurate data.
Data Pipeline Architecture Explained: More Than Just Moving Data
Before diving into patterns and design decisions, it helps to understand what data pipeline architecture covers. Fundamentally, it is the outline of data flow (in terms of ingestion to transformation to delivery) and systems, tools, and rules governing that data flow.
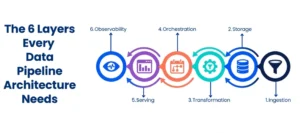
A typical data pipeline architecture consists of multiple layers that are interconnected:
1. Ingestion Layer
This is where the data is received in the pipeline by its sources: databases, APIs, SaaS platforms, IoT sensors, event streams, and flat files. Ingestion layers should be able to support both the batch loads (large, scheduled data pulls) and real-time streaming (continuous, low-latency feeds). Subsequent ETL techniques, such as Change Data Capture (CDC) are becoming popular in this area to record incremental changes to the database without overwhelming source systems.
2. Storage Layer
After being ingested, data must have a place to rest; it can be a data lake where raw, unstructured data is stored, or a data warehouse where the data is structured, query-ready data. A frequently used modern architecture of cloud data pipelines adopts a lakehouse model, a combination of a lake and a warehouse. Popular options at this layer are platforms such as Snowflake, Databricks, BigQuery, and Amazon S3.
3. Data Transformation Pipeline
Raw data is seldom in a useful form. It is transformed into a form that can be actually used by either an analyst, an AI model, or operational systems through the transformation layer, where it is cleaned, normalized, deduplicated, enriched, and structured into forms that can actually be used by an analyst, an AI model, or operational systems. One of the most logical intensive components of the architecture is the data transformation pipeline – and the place where the most things can go awry unless controlled well.
4. Orchestration Layer
The process of coordination in the whole pipeline is orchestration. Apache Airflow, Prefect, and Dagser can be used to schedule jobs, depend on tasks, retries, and provide an engineer with insights into what has already been run, at which time, and with what outcome. Devoid orchestration, pipelines become a shaky arrangement of scripts, of which no one has the slightest idea or belief.
5. Serving and Delivery Layer
It is here that processed data is sent to its destiny, a BI application, such as Tableau or Power BI, a machine learning application, a CRM, or an operational dashboard in real-time. The serving layer defines how consumers access data and in what format.
6. Observability and Monitoring
The modern data pipeline architecture considers observability as a fundamental aspect, as opposed to an afterthought. It involves monitoring data freshness, volume anomalies, schema changes, and pipeline failures – this way, business decisions are made before problems arise.
Modern Data Engineering Pipeline Patterns You Actually Need to Know
The pipeline required by not all organizations is the same. The correct architecture is based upon the business case, data size, latency needs, and technical maturity. The following are the most popular patterns at present:
ETL Pipeline Design (Extract, Transform, Load)
The traditional ETL pipeline design is a configuration that pulls data out of the source systems, transforms data in a staging environment, and finally loads the purged data into a warehouse. This is an effective method when the workload is more structured, predictable, and the transformation logic is complex or cannot be executed within the warehouse itself. It continues to be used in many controlled sectors, such as financial and medical.
ELT (Extract, Load, Transform)
Most cloud-native data engineering pipelines have been replaced with ELT. ELT loads raw data into the warehouse and transforms it there, rather than pre-transforming data before loading, typically using the built-in compute of the warehouse, typically SQL or a tool like dbt. The latter is quicker to apply, stores raw data to be reprocessed, and leverages the scalable cloud infrastructure to the fullest.
Streaming-First Data Pipeline Architecture
Streaming architecture Process Data in streaming architecture is used in applications where time-scale is important, such as fraud detection, live personalization, IoT monitoring, etc. Its tools, such as Apache Kafka, Apache Flink, or AWS Kinesis, can process data in real-time, especially for continuously moving data. Such a data pipeline architecture can provide the answer to the question of what is going on at the moment and not what happened last night.
Batch + Streaming Hybrid
Most production settings come to rest at a hybrid model, time-sensitive ingestion with streaming and resource-intensive transformations with batch processing. This is an archetypal trend in cloud data pipeline architecture since it represents a scaling between latency demands and cost-effectiveness.
Lambda and Kappa Architectures
Lambda architecture runs batch and streaming layers in parallel, merging results at the serving layer. Kappa architecture simplifies this by using a single streaming layer for everything. Kappa is increasingly favored in modern data engineering pipeline design because it reduces operational complexity.
Reverse ETL
Reverse ETL pipelines sync modeled, analytics-ready data back into operational tools — CRMs, marketing platforms, customer success tools. This closes the loop between analytics and action, enabling real-time personalization and automated business workflows driven by warehouse data.
Cloud Data Pipeline Architecture: Why Cloud-Native Thinking Changes the Design
Cloud-native practices have transformed how data pipeline architecture is designed, deployed, and scaled. Storage and compute separation. The concept of storage and compute being decoupled with a platform, such as Snowflake, allows organizations to scale query performance without increasing storage spend and vice versa. This is one design principle that opens up an aspect of flexibility that cannot be matched with an on-premises architecture.
The main features of the present-day cloud computing data pipeline are:
- Elastic scalability – resources are automatically increased or decreased with load.
- Serverless execution – no infrastructure operation of a single pipeline job.
- Native integrations – Integrity of cloud-native storage, compute, and orchestration tools.
- Cross-cloud data sharing – Services such as Snowflake can share data with no copying between organizations and between clouds.
- Built-in observability – managed services are starting to provide monitoring, alerting, and lineage tracking as default features.
In organizations operating multi-cloud environments, which have become the standard of large organizations, the architecture of cloud data pipelines also needs to support data flow between AWS, Azure, and Google Cloud without lock-in or unwarranted duplication.
Data Pipeline Frameworks: Matching the Right Tool to the Right Layer
The data pipeline frameworks ecosystem has grown tremendously. The selection of the correct combination of tools does not have much to do with a preference for a vendor, but rather with fitting with the architecture layer to which a tool is best suited.
The way the modern stack is usually subdivided into layers is as follows:
- Ingestion: Fivetran, Airbyte, Stitch, Apache Kafka, AWS DMS.
- Storage: Snowflake, BigQuery, Amazon S3, Databricks, Azure Synapse.
- Transformation: dbt, Apache Spark, AWS Glue, Databricks Notebooks.
- Orchestration: dbt Cloud, Apache Airflow, Prefect, Dagster.
- Observability: Monte Carlo, Great Expectations, Atlan, Alation.
The right data pipeline frameworks are not universal – they are dependent on the technical depth of your team, cloud provider, and the latency needs of your use cases.
Building Data Pipelines for AI and Analytics: The Requirements Have Changed
The emergence of AI-driven workloads is, perhaps, one of the most important changes in the data pipeline architecture in the last two years. The process of training machine learning models, executing AI agents for data analysis, and allowing inference in real-time imposes a load on pipelines that traditional architectures were not designed to support.
AI and analytics data pipelines must meet demands that are even more stringent than regular reporting pipelines:
- Feature consistency: both training and inference data should be produced by the same pipeline logic.
- Data versioning: models need to be traceable to the specific dataset they were trained on.
- Low-latency serving: AI programs that need real-time data delivery need sub-second responses.
- Unstructured data handling: AI systems tend to process text, images, and documents in addition to structured records; they need vector pipelines and RAG (Retrieval-Augmented Generation) infrastructure.
AI Agents for data analysis are now directly integrated into pipeline processes, not only as a consumer of pipeline outputs, but also as an active user of data quality monitoring, anomaly detection, and recommended transformations. This is one of the basic changes in what data pipeline architecture should be able to facilitate.
What Makes Data Pipeline Architecture Actually Fail — And How to Avoid It
Most pipeline failures aren’t dramatic. They’re slow, quiet, and expensive — incorrect data accumulating in a warehouse, a pipeline running hours late, a schema change upstream breaking five downstream jobs silently. Here are the most common architectural mistakes that cause these problems:
Skipping observability from the start.
A pipeline that breaks without alerting is often worse than no pipeline at all — it produces incorrect results that get used without question. Observability isn’t optional in production data pipeline architecture.
Treating transformation as secondary.
The data transformation pipeline is where most business logic lives. Poorly designed transformation layers become unmaintainable quickly — especially when multiple teams are writing SQL with no shared standards.
Not planning for schema evolution.
Source systems change. APIs add fields, remove columns, and rename things. Pipelines that can’t adapt gracefully will break at the worst possible moment.
Over-engineering early.
A Lambda architecture with dual batch and streaming layers sounds impressive. But if your actual use case can tolerate a two-hour delay, you’ve just built yourself years of unnecessary operational complexity.
Building without data governance.
Without lineage tracking, quality checks, and access controls, a data pipeline architecture creates compliance risk and trust problems — especially in industries like finance and healthcare.
Conclusion
The data pipeline architecture is no longer a back-end technical issue. It is the layer in the infrastructure that dictates how quickly and confidently an organization can act on its data. Between deciding between ETL and ELT and creating cloud-native systems that enable AI, each architectural choice impacts the quality of analytics, speed of operations, and business performance downstream. Today, organizations that invest in considerate, scalable, and observable pipeline design will be much better placed to create AI-ready infrastructure tomorrow. In case you have weak, isolated, or failing-to-meet-the-increasing-data-volume pipelines, begin with the architecture. AnavClouds Analytics.ai introduces a strong proficiency in data engineering services, AI development services, and data architecture consulting to assist organizations in planning and executing pipelines built to last.
FAQs
What is data pipeline architecture?
Data pipeline architecture is the organized architecture of data movement systems – the way data is ingested, stored, transformed, and delivered to analytics or AI workloads. It determines the tools, patterns, and rules that govern the whole data flow.
What is the difference between ETL and ELT in data pipeline design?
Data transformation in the design of ETL pipes is followed by loading the data into a destination system. ELT loads raw data and transforms it within the warehouse using its native compute. ELT is now the new data engineering pipeline of choice in cloud-native environments since it is more scalable, faster to deploy, and it leaves raw data to be re-processed.
How does cloud data pipeline architecture differ from on-premises?
Cloud data pipeline architecture divides storage and compute so that they can scale independently. It also facilitates serverless execution, elastic resource management, and native integrations among cloud services – features that on-premises architectures cannot easily replicate. Pipelines on the cloud are also quicker to implement and monitor.
When do you need a real-time data pipeline architecture?
When your application needs an immediate response to new data, e.g., fraud detection, real-time recommendations, IoT monitoring, or AI inference, then you will need a real-time data pipeline architecture. An acceptable delay added by batch processing (say, nightly financial reports) can be an unnecessary complication and cost to a streaming architecture.


