


The data is just as valuable as the pipeline that can be used to access it. When it comes to pipeline construction, few decisions are as important as the choice between ETL vs ELT. These two styles of data integration are more than just acronyms; they represent two different philosophies regarding where, when, and how to perform the data transformation before it can be used to make business decisions. The right answer and data stack become a competitive advantage. You’ll be spending months troubleshooting infrastructure that is not scalable if you get it wrong. This blog explores the practical aspects of the ETL vs ELT discussion, including architecture, speed, compliance, AI readiness, and determining which method is most appropriate for your 2026 stack.
Why the ETL vs ELT Conversation Matters More Than Ever
The data integration software market expanded by 9.8% in 2024 to reach $5.9 billion, with much of this growth attributed to the transition to AI-enabled data pipelines and cloud-native ecosystems. With organizations racing to build a scalable, intelligent data infrastructure, the ETL vs ELT distinction has become a no-brainer, rather than a nice-to-have. Gartner
Both methods load data from a source to a destination for analysis. The one thing that makes them different is the WHEN and WHERE the transformation takes place. This one difference trickles through to speed, cost, compliance posture, and long-term data readiness for AI.
What Is ETL? Understanding the Traditional Pipeline
ETL is an acronym for Extract, Transform, Load. The series is deliberate and sequential:
Extract — Raw data is pulled from the source systems: relational databases, CRMs, ERPs, flat files, SaaS applications, and more.
Transform —The data is cleaned, reformatted, deduplicated, and restructured on a separate processing server before it reaches its destination. Only data that has passed a set of rules advances.
Load — The data is then loaded to the target data warehouse system, ready to be used for reporting and analysis.
ETL pipelines have been an integral part of enterprise data engineering since the 1970s. It provided organizations with control, particularly in cases where data quality, schema consistency, and regulatory compliance were critical. As long as structured data is piped into legacy warehouses, the ETL pipe is very reliable.
ETL works best when:
- Data is organized and has consistent schemas.
- Data must be masked or filtered before it is stored for compliance.
- Infrastructure: Legacy DW systems or On-premise
- Data volumes are unchanging and moderate.
- Analytics use cases are clearly defined at the beginning.
What Is ELT? The Cloud-Native Evolution
ELT inverts Extract, Load, Transform. That’s an arrangement that changes everything.
Extract — Data is taken from the same set of source systems.
Load — Raw, unprocessed data is loaded directly into the destination — usually a modern cloud data warehouse, or data lake.
Transform — Transformation is done in the destination system, on the fly, and based on the processing power of the destination system.
Cloud options such as Snowflake, Google BigQuery, Amazon Redshift, and Databricks made the ELT process a reality by enabling the storage of terabytes of raw data at a low cost and processing that data on elastic, scalable compute. No longer is there a transformation server that becomes the bottleneck, but the warehouse performs the heavy lifting.
The ELT strategy excels when:
- You’re running on a cloud-native/on-premises data stack.
- Data quantities are substantial, unpredictable or changing quickly
- In real-time processing scenarios, such as live dashboards or streaming, you require real-time data processing.
- You are working with unstructured or semi-structured data (such as JSON, logs, images, IoT streams).
- Your AI/ML pipelines require access to a high volume of raw, diverse data
ETL vs ELT: A Side-by-Side Breakdown
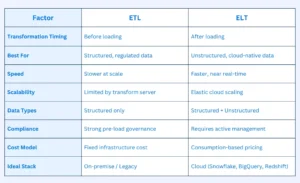
Understanding ETL vs ELT across the dimensions that actually affect your architecture helps cut through the noise. Here’s how the two compare where it matters:
Transformation Location
In an ETL pipeline, transformation happens on an intermediary server before the data reaches the warehouse. Your destination always sees clean, structured data — but your transformation logic must be defined upfront and rebuilt whenever requirements change.
In an ELT strategy, raw data lands in the warehouse first. Transformation happens there — using SQL, dbt, or similar tools — and can be re-run as many times as needed without re-extracting from the source. This flexibility is one of ELT architecture’s most underrated advantages.
Speed and Latency
The ETL vs ELT speed gap is significant in high-volume environments. ETL adds a transformation step before loading, creating sequential latency that scales poorly as data grows. The larger the dataset, the longer the pipeline takes to complete.
ELT loads data immediately and transforms in parallel using cloud compute. This makes real-time data processing achievable in ways ETL simply cannot match at scale. For use cases like live fraud detection, dynamic pricing, or personalized recommendations, ELT’s speed advantage is decisive.
Scalability
Scaling an ETL pipeline means scaling the external transformation infrastructure — a separate system that grows linearly with data volume and adds cost with it.
ELT scales with your cloud warehouse. Platforms like Snowflake and BigQuery offer compute elasticity — scale up during heavy transformation jobs, scale down when idle. No separate infrastructure to maintain. This is why the ETL vs ELT scalability comparison consistently favors ELT for modern, cloud-native data engineering services.
Data Type Flexibility
ETL was built for structured, tabular data. It transforms data into a predefined schema before loading, which works well when your data is clean and consistent. But it struggles with unstructured formats.
The ETL vs ELT contrast here is sharp: ELT handles structured, semi-structured, and unstructured data natively. Images, JSON objects, log files, IoT sensor streams, and text documents all land in the data lake as raw inputs — and can be queried or transformed as business needs evolve. This flexibility is central to why ELT has become the default for AI development services and ML pipelines.
Compliance and Governance
ETL holds a meaningful advantage in regulated industries. Because transformation and masking happen before loading, sensitive fields — PII, financial records, healthcare data — can be stripped or encrypted before they ever reach the warehouse. This satisfies GDPR, HIPAA, and similar frameworks at the structural level.
In the ETL vs ELT compliance comparison, ELT requires more careful governance. Raw data sits in the warehouse temporarily before it’s transformed or masked, meaning your cloud platform’s access controls, encryption policies, and audit capabilities must be tightly configured. It’s manageable — but it requires active effort rather than passive protection.
Cost Structure
The ETL vs ELT cost equation depends on how you use each approach.
ETL incurs fixed costs for transformation infrastructure — servers that run whether your pipelines are active or not. For predictable, moderate-volume workloads, this can be cost-efficient. But as data grows, those costs scale linearly.
ELT typically runs on consumption-based cloud pricing. You pay for compute when transformations run, not for idle servers. The trade-off: inefficient transformation queries in a cloud warehouse can spike costs quickly. Proper query optimization and selective transformation are essential to keeping ELT economical at scale.
ETL vs ELT and AI Readiness: A 2026 Priority
This is where the ETL vs ELT debate takes on particular urgency today. AI models — from classical machine learning to large language models — need access to raw, high-volume, diverse data. Transformation schemas defined months before a model is built can create serious limitations for data scientists who need to iterate quickly on features and training data.
Data readiness for AI strongly favors ELT. Raw data preserved in a data lake gives teams the flexibility to re-transform, re-query, and re-engineer features without re-extracting from source systems. When combined with proper data quality controls, ELT architecture creates the kind of AI-ready data pipelines that modern ML workflows demand.
The ETL vs ELT decision in an AI context is also about iteration speed. AI teams that can’t access or reprocess raw data quickly are perpetually behind. ELT removes that bottleneck, making it the natural foundation for data pipeline architecture designed with AI workloads in mind.
That said, data quality remains the one constant regardless of which approach you choose. AI doesn’t tolerate dirty data any more under ELT than under ETL. Robust validation, lineage tracking, and quality checks must be built into any data integration approach — ELT included.
Industry Applications: Where Each Approach Fits
Financial Services: Transaction data and audit trails may be transported through ETL pipelines for regulatory reasons. ELT’s speed and raw data access are, however, essential to power real-time risk scoring and fraud detection models, which feed into the streaming data pipeline architecture.
Healthcare: Patient data containing PHI can travel from system to system via ETL, with attention given to ensuring that PHI is masked for storage. ELT processes large-scale imaging, genomic, and sensor data through population health analytics and AI diagnostics platforms in cloud data lakes.
Retail and E-Commerce: ETL is used to structure sales and inventory data into business intelligence services dashboards. ELT is used for real-time data processing at scale for customer behavior streams, clickstream data, and training the recommendation engine.
Manufacturing: ELT sends IoT Sensor data from shop floors to data lakes for predictive maintenance models. Financial data and supply chain data go into structured reporting domains as ETL.
Choosing Your Data Integration Approach
The ETL vs ELT choice isn’t a universal verdict — it’s a context-specific decision. Here’s a framework to guide it:
Choose ETL when:
- You operate in a compliance-heavy industry with strict pre-load data governance requirements
- Your data is primarily structured, and schemas are stable
- Your infrastructure is on-premises or uses legacy systems with limited compute
- Data volumes are moderate, and the transformation logic is well-defined upfront
Choose ELT when:
- You’re cloud-native or actively migrating to cloud infrastructure
- You need real-time data processing or near-real-time analytics
- Your data is diverse — unstructured, semi-structured, or high-volume
- You’re building or scaling AI, ML, or advanced analytics capabilities
- You need the flexibility to evolve transformation logic over time
Consider a hybrid data integration approach when: Both apply. Many mature organizations use ETL for compliance-sensitive streams and ELT for cloud analytics and AI workloads — running them in parallel under a unified orchestration layer. This is increasingly common in enterprises with complex, multi-domain data environments and is supported by modern data engineering services platforms that handle both patterns natively.
Conclusion
The ETL vs ELT conversation ultimately comes down to knowing your data, your infrastructure, and your goals. Neither approach is universally superior — ETL still wins where governance and structure demand it, and ELT leads where speed, scale, and AI readiness matter most. What’s clear in 2026 is that the organizations building the strongest data foundations are the ones making this choice deliberately, not by default. At AnavClouds Analytics.ai, we help enterprises evaluate and implement the right data pipeline architecture — whether that’s ETL, ELT, or a hybrid strategy — so your data works harder, moves faster, and stays ready for whatever AI throws at it next
FAQs
What is the main difference between ETL and ELT?
The key distinction between ETL vs ELT is the sequence of transformations. ETL applies transformations to data before loading it into the target system, running on a separate processing server. By loading raw data first, ELT loads the data into the data warehouse or data lake. The only difference that impacts the speed, flexibility, compliance, and cost of the data pipeline.
Is ELT better than ETL for cloud environments?
Generally, yes. ELT is specifically designed for cloud data warehouses such as Snowflake, BigQuery, and Redshift that offer elastic compute to transform data in the data warehouse at scale. While ETL can function in the cloud, ELT’s architecture is more cloud-friendly and real-time data processing-friendly.
Which approach is better for AI and machine learning pipelines?
ELT has an obvious edge in ETL vs ELT for AI workloads. It maintains raw data in scalable data lakes and enables the transformation logic to be updated as the model changes based on new requirements of the data. ETL’s rigid transformation schemas can hinder AI readiness and impede ML development cycles.
Can businesses use both ETL and ELT at the same time?
Yes, and many do. A hybrid data integration approach, where ETL is used for compliance-driven or legacy data streams, and ELT for cloud-based analytics and AI pipelines, is becoming increasingly common for enterprise data environments. There’s no one-to-one correspondence between ETL vs ELT modern orchestration platforms can handle both patterns under a common data pipeline structure.


